Machine Learning - Week1 Parameter Learning
Machine Learning Week1 - Model and Cost Function の続き
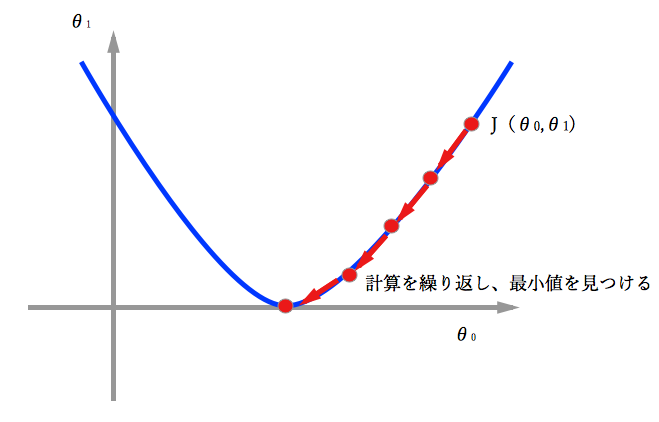
前回でてきたの最小を見つける目的関数の中の、最急降下法(Gradient Descent)を扱う。
最急降下法(Gradient Descent)
関数(ポテンシャル面)の傾き(一階微分)のみから、関数の最小値を探索する連続最適化問題の勾配法のアルゴリズムの一つ
アルゴリズム
- 適当な
を選ぶ
初期値はなんでもいい。 がまだ最小値でなければ、次の
- 2に戻る
※ 初期値次第は、局所的最適解(local minimum)が異なることもある
グラフにすると
数式
いきなり微分がでてくるけど、重要なのはが何か
シンボルの意味
代入を表す
はaにbを代入することとなるが、
はaはbと等価である意味なので注意
学習率(Learning rate)を表す
最急降下法は何回も計算しながら最適解を見つけるが、その1回1回のステップの距離にあたる- αが大きい
大きなステップとなり、高速にはなるが、うまく収束(conversion)しないか、発散(diverge)することも - αが小さい
小さなステップとなり、ステップが増え収束に時間がかかってしまう
- αが大きい
導関数項(derivative term)を表す
現在地()があって、次に低い地点に進むにはどっちに向かえばいいかを決めるパラメータ
導関数の公式の証明の前に、そもそも導関数とは何だろうか?導関数とは、ざっくりと言ってしまえば、グラフの傾きの事なのです。つまり、先ほど紹介した導関数の公式は、グラフの傾きを表していたわけです。
 を算出する上での注意事項
を算出する上での注意事項
と
は同時(simultaneous)に更新する
数式にと
が混在しているが、
を計算して、その
の値で
を求めるのはNG.
まぁここは中で出てくる演習問題を解く事で理解できる.