Machine Learning Week1 - Model and Cost Function
Machine Learning Week1 - Introduction の続き
このレッスンは、線形回帰の中でもシンプルな一変数による線形回帰(Linear Regression with One Variable)がターゲット
「住宅の広さ(x)から、家賃(y)を予測する」時のように、「一つの変数xから、全体の結果を予測する」 ような二次関数の導き方を学習する。 = 単回帰(Univariate linear regression)

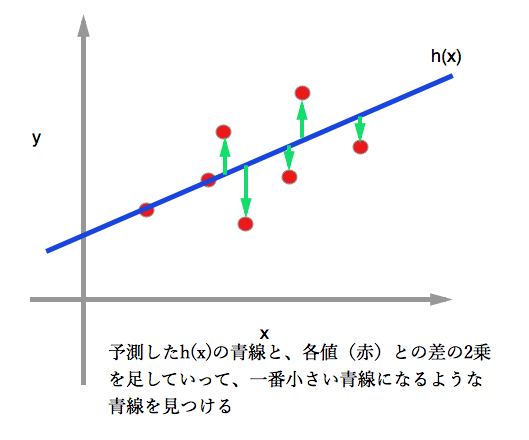
データが上図の赤点だとすると、二乗誤差目的関数というのを使って、妥当な二次関数(青線)が評価できるようになる。
表記(シンボル)
今後の数式で出てくる表記が何を示すのか理解しておく
: 訓練サンプルの数(Number of training examples)
: 入力変数(input variable / features)
: 出力変数(output variable / target variable)
: 一件の訓練サンプル(one training example)
: i番目の訓練サンプル
: 予測(hypothesis)関数
-> hは入力変数を出力変数へ対応させる関数 (h maps from x's to y's)
予測関数
予測関数とは上図でいう青線にあたるもの。以下のような数式で表す
↓ 短縮系

パッと見難しいけど、ようは二次関数(y=ax + b)の形。
は初期値(b)のことで、
はxの傾き具合(a)のこと。
このの最適解を求める関数を目的関数(cost function)と呼び、このレッスンで扱う
二乗誤差目的関数もその一つ。
二乗誤差目的関数
数式にするとこれ
二乗誤差目的関数は、この が最小の値になるようなパラメータ(
)を見つけていく目的関数。=>
※ 二乗誤差 => 図乗の緑で示した差(誤差)を二乗しているから
Ng「なぜ二乗するのでしょう?」
Ng「これが妥当な選択(reasonal choice)だから」
(´・ω・`)なんじゃそりゃ…
残差を最小にするような最小二乗法で求めた推定値が、不偏で最小の分散を持つことを保証する定理である
参考:最小二乗法は、なぜ「二乗」なのでしょうか? - 数学 | 教えて!goo
 だった場合の最適解
だった場合の最適解
の場合は、
と二乗誤差の関係を図にすると以下のようになる。
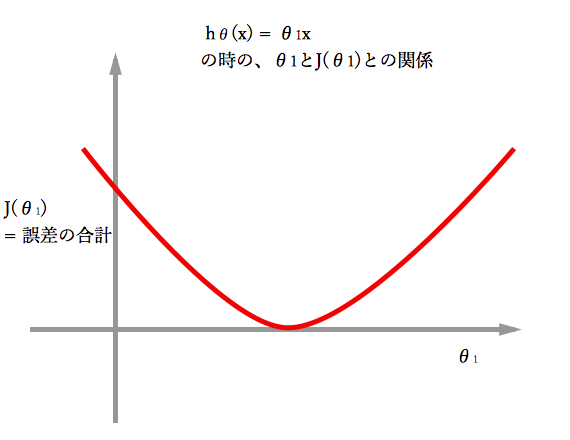 つまり二乗誤差目的関数はある一点の最適解だけがある状態となる。(シンプル
つまり二乗誤差目的関数はある一点の最適解だけがある状態となる。(シンプル
 だった場合の最適解
だった場合の最適解
パラメータがと
になるので、
及び
と二乗誤差の関係はボウル型の三次元となる.
この3次元での最小値は、次で学習する最急降下法(Gradient Descent)を使って求めていく
参考にしたサイト
目的関数 : はじめての最適化(第1回)